
Mozilla has released an open source voice recognition tool that it says is “close to human level performance,” and free for developers to plug into their projects.
The free-software company also on Wednesday released a first set of crowdsourced recordings under its Common Voice project, designed to let anyone train and test machine learning algorithms to recognize speech. The dataset includes almost 400,000 downloadable samples, adding up to 500 hours of speech. More than 20,000 people from around the world have contributed to a call for recordings, which Mozilla hopes will help future voice-powered systems fluently understand a wide variety of accents and types of speech. “We at Mozilla believe technology should be open and accessible to all, and that includes voice,” Mozilla Senior Vice President of Emerging Technologies Sean White wrote in a blog post.
The speech recognition tool, called DeepSpeech, has an impressive per-word error rate of about 6.5%, ahead of the company’s stated goal of 10%, but still shy of Microsoft’s achievement this year of 5.5%. Implemented with TensorFlow, an open source machine learning tool released by Google, the Mozilla model uses the “deep learning” multilayer neural network approach that’s been successful at a wide range of artificial intelligence tasks, and is based on a 2014 research paper from scientists at Baidu, the Chinese internet giant.
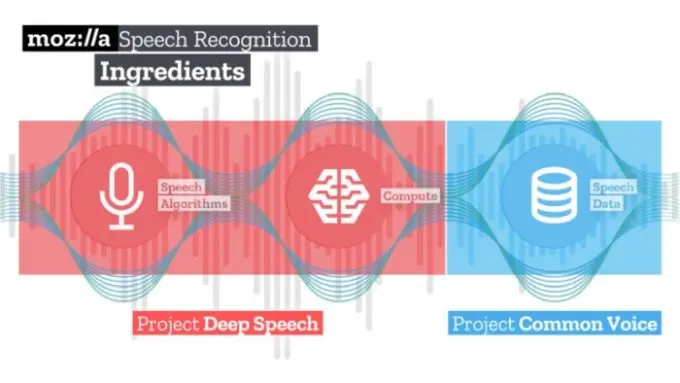
Through its public crowdsourcing approach, Mozilla has sought to build datasets that researchers and developers around the world could share freely, letting them easily compare results and test across a diverse, public sample of speech—minus some of the privacy concerns that come with large corporate speech-collection efforts.
“If you wanted to do a new speech-recognition system, you couldn’t just go out and find a high-quality data set to use,” White told me a few months ago. At that point, the project’s data had already surpassed the full audio corpus of TED Talks, one of the internet’s largest open source voice data sets. (You can read more about Mozilla’s Common Voice effort in my story here.)
Recognize your brand’s excellence by applying to this year’s Brands That Matter Awards before the early-rate deadline, May 3.
